La arquitectura hexagonal o de puertos y adaptadores consta de 3 capas:
- Infraestructura: Lo que conecta nuestra capa de aplicación con la entrada y salida de información: base de datos, HTTP, message’s queues, etc.
- Aplicación: Donde residen nuestros casos de uso
- Dominio: Aquí encontramos cosas como nuestras entidades
Por que puertos y adaptadores?
Podemos decir que los puertos son las interfaces de entrada y salida de nuestra aplicación. Una API JSON, un consumidor de un Message Queue, etc.
Por su parte, los adaptadores conectan nuestra lógica de negocio para que pueda ser consumida o ejecutada por otros actores (usuarios o sistemas).
Digamos que un controlador es un adaptador.
¿Cómo se reflejan estas capas en una aplicación típica de Phoenix?
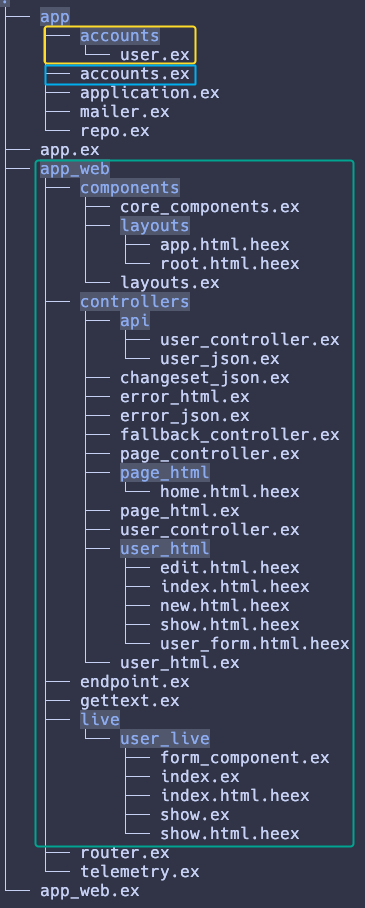
Nuestros schemas como el de user son parte del dominio.
Mientras que los context modules como el de accounts podríamos decir que forman parte de la capa de aplicación.
Finalmente, lo que está contenido en app_web/ formaría parte de la capa de infraestructura, al igual que el modulo repo y el mailer.
Capa de dominio
¿Cómo modelamos la capa de dominio?
Respuesta corta: Usamos Domain-Driven Design (DDD) para descubrir los subdominios del negocio y diseñar bounded contexts. Chris McCord abordo este tema en su keynote en la ElixirConf 20171:
app/
├─ ecommerce/
│ ├─ accounts/
│ │ ├─ schemas/
│ │ │ ├─ user.ex
│ │ │ ├─ user_token.ex
│ │ ├─ accounts.ex
│ ├─ catalog/
│ │ ├─ schemas/
│ │ │ ├─ category
│ │ │ ├─ product.ex
│ │ ├─ catalog.ex
│ ├─ shopping_cart/
│ │ ├─ schemas/
│ │ │ ├─ cart.ex
│ │ │ ├─ cart_item.ex
│ │ ├─ shopping_cart.ex
├─ backoffice/
│ ├─ support/
│ │ ├─ schemas/
│ │ │ ├─ ticket.ex
│ │ ├─ tickets.ex
├─ app_web/
│ ├─ controllers/
│ │ ├─ ecommerce/
│ │ │ ├─ product_controller.ex
│ │ │ ├─ category_controller.ex
│ │ ├─ backoffice/
│ │ │ ├─ ticket_controller.ex
│ │ │ ├─ product_controller.ex
│ │ │ ├─ category_controller.ex
├─ README.md
En este ejemplo hay dos grandes contextos: ecommerce y backoffice. Pero eso no significa que no puedan surgir más, como marketing, ventas, etc.
A su vez, tanto ecommerce como backoffice contienen el directorio schemas/ (dominio) y un context module (aplicación): API’s públicas para interactuar con los esquemas.
Esta separación en contextos nos permite aumentar la cohesión de nuestro código. Al tener todos los conceptos relacionados cerca: usuario y token, producto y categoría, etc. Mientras que como veremos más adelante, tener una capa de aplicación nos permite reducir el acoplamiento, al separar los casos de uso de quien los llama, sea una interfaz de usuario o una interfaz para sistemas externo.
Una pregunta que puede surgir es: ¿Por qué tenemos un product_controller.ex tanto en ecommerce como en backoffice?
Porque una entidad no necesariamente significan lo mismo en distintos contextos. Un producto puede diferir en algunas características para un cliente en ecommerce que para un usuario interno en el backoffice.
Un lead puede ser apenas un registro en un formulario para marketing, mientras que para ventas es alguien que paso por el embudo de ventas, conteniendo mucha más información.
Capa de aplicación
Tener una capa de aplicación nos permite tener límites bien definidos acerca de cómo acceder a la lógica de negocio. Registro, Login, etc.
Los generadores de Phoenix crean context modules que podríamos considerar como nuestra capa de aplicación. Por ejemplo Accounts.
app/
├─ ecommerce/
│ ├─ accounts/
│ │ ├─ accounts.ex
│ ├─ catalog/
│ │ ├─ catalog.ex
│ ├─ shopping_cart/
│ │ ├─ shopping_cart.ex
├─ backoffice/
│ ├─ support/
│ │ ├─ tickets.ex
├─ app_web/
├─ README.md
Son la API publica para interactuar con nuestros esquemas de ecto.
Si quisiéramos introducir nuevos casos de uso podemos hacer algo como lo siguiente.
Vamos a crear un nuevo directorio services
app/
├─ ecommerce/
│ ├─ accounts/
│ │ ├─ services/
│ │ │ ├─ user_creator.ex
...
services es basicamente un service layer:
Defines an application’s boundary with a layer of services that establishes a set of available operations and coordinates the application’s response in each operation.
Es una forma de encapsular nuestros casos de uso, en este caso crear un usuario.
El módulo user_creator.ex es el que define las operaciones y coordina la respuesta, siguiendo el patrón ThingDoer-do_thing.
defmodule App.Ecommerce.Accounts.UserCreator do
alias App.Ecommerce.Accounts
alias App.Ecommerce.Accounts.User
alias App.Ecommerce.Accounts.ConfirmationEmailJob
alias App.Ecommerce.Accounts.UserEmail
alias App.Mailer
def create_user(email, password) do
with {:ok, user} <- Accounts.create_user(email, password),
{:ok, _job} <- ConfirmationEmailJob.enqueue(user) do
{:ok, user}
end
end
def send_confirmation_email(%User{} = user) do
email = UserEmail.confirmation(user)
Mailer.deliver(email)
end
end
El patrón ThingDoer-do_thing nos permite evitar funciones genéricas y ambiguas como: call, run, o execute, haciendo que nuestro código comunique su comportamiento. Cabe mencionar que el módulo UserCreator no contiene lógica en sí mismo, sino que orquesta los módulos necesarios para cumplir con el caso de uso.
Otro beneficio del service layer es que proporciona una costura:
a seam is a place where you can alter behavior in your program without editing in that place
Si nuestra lógica de negocio acerca de crear usuarios cambia, dichos cambios no tendrán nada que ver con el controlador o el background job.
Capa de infraestructura
La responsabilidad de la capa de infraestructura es validar y normalizar la información que se recibe, de forma que la aplicación y el dominio puedan trabajar con ella.
Como nuestra capa de aplicación define las operaciones disponibles, estas se pueden reutilizar en distintos adaptadores, lo que permite que nuestra aplicación reciba información y responda en el formato adecuado sin importar de donde provenga, ya sea una API JSON, un background job, un Liveview, un evento de dominio, message queues, etc.
Infraestructura es otro nombre para lo que Saša Jurić llama Interfaz en su serie de artículos Towards Maintainable Elixir: The Core and the Interface.
En la sección anterior agregamos algunos modulos nuevos y sus respectivos directorios:
app/
├─ ecommerce/
│ ├─ accounts/
│ │ ├─ jobs/
│ │ │ ├─ confirmation_email_job.ex
│ │ ├─ emails/
│ │ │ ├─ user_email.ex
...
jobs Es un directorio para definir background jobs.
El módulo confirmation_email_job.ex es un background job para agregar confiabilidad al envío del email de confirmación.
emails Bibliotecas como swoosh nos permiten construir emails mediante funciones, de esta forma el módulo user_email.ex puede definir distintos tipos de emails relacionados con el usuario.
Por otro lado, los backgrounds jobs son parte de nuestra capa de infraestructura, por lo que evitamos definir lógica de negocio en ellos. En su lugar se comunican con la capa de aplicación por medio de nuestro service layer :D
defmodule App.Accounts.ConfirmationEmailJob do
use Oban.Worker, queue: :default
alias __MODULE__
alias App.Ecommerce.Accounts
alias App.Ecommerce.Accounts.UserCreator
def enqueue(%{id: id} = args) do
args
|> ConfirmationEmailJob.new()
|> Oban.insert()
end
@impl Oban.Worker
def perform(%Oban.Job{args: %{"id" => user_id} = args}) do
user = Accounts.get_user!(user_id)
UserCreator.send_confirmation_email(user)
end
end
Supongamos que nuestra aplicación es SSR por lo que nuestras respuestas son en HTML:
defmodule AppWeb.UserSchema do
use Goal
defparams :new do
required :email, :string
required :password, :string
end
end
defmodule AppWeb.Ecommerce.UserController do
use AppWeb, :controller
alias AppWeb.UserSchema
alias App.Ecommerce.Accounts.UserCreator
def create(conn, %{"user" => user_params}) do
with {:ok, attrs} <- validate(:new, user_params),
{:ok, user} <- UserCreator.create_user(attrs.email, attrs.password) do
{:ok, user} ->
conn
|> put_flash(:info, "User created successfully.")
|> redirect(to: ~p"/users/#{user}")
else ->
{:error, %Ecto.Changeset{} = changeset} ->
render(conn, :new, changeset: changeset)
end
end
end
Pero, ademas abrimos la posibilidad a que otras aplicaciones consuman nuestra lógica de crear usuarios mediante un API REST, donde nuestra respuesta es en formato JSON:
defmodule AppWeb.UserSchema do
use Goal
defparams :new do
required :email, :string
required :password, :string
end
end
defmodule AppWeb.API.Ecommerce.UserController do
use AppWeb, :controller
alias AppWeb.UserSchema
alias App.Ecommerce.Accounts.UserCreator
action_fallback AppWeb.FallbackController
def create(conn, %{"user" => user_params}) do
with {:ok, attrs} <- validate(:new, user_params),
{:ok, user} <- UserCreator.create_user(attrs.email, attrs.password) do
conn
|> put_status(:created)
|> put_resp_header("location", ~p"/api/users/#{user}")
|> render(:show, user: user)
end
end
end
Creo que se entiende la idea ;). El punto de entrada a nuestra lógica de negocio es el mismo y el código al rededor es acerca de como responder adecuadamente al formato solicitado.
En estos ejemplos el controlador recibe un mapa que puede contener campos desconocidos o puede haber campos faltantes. Usando la biblioteca Goal nos aseguramos que los campos que necesita nuestra capa de aplicación estén presentes y sean de un tipo correcto, además transforma las llaves a átomos :D.
Por lo que nuestro caso de uso no tendrá que lidiar con información invalida y como es convención en Phoenix, las reglas de negocio como que el email sea único y el password sea suficientemente largo se encuentran más cerca del dominio mediante Ecto Changesets.
Esto tiene la ventaja de que nos aseguramos que estas reglas se cumplan sin importar la interfaz de entrada.
Nótese que ninguno de los módulos contiene Schemas, .Services, .Emails o .Jobs, de la misma forma en que en Phoenix los controladores no llevan .Controllers.
Sería un poco raro ver un controlador App.Ecommerce.Controllers.UserController, de la misma forma evitamos cosas como App.Accounts.Jobs.ConfirmationEmailJob.
Otros menesteres
Hay algunos conceptos como la autorización que pueden ser transversales a nuestra aplicación.
app/
├─ ecommerce/
├─ backoffice/
│─ access_control.ex
...
Podemos promover ese tipo de módulos a nuestra “raíz”, dando a entender que abarca toda nuestra aplicación.
Otro caso común es cuando nuestros módulos, como Accounts o Catalog comienzan a tener cada vez más métodos para cubrir distintos escenarios o para abarcar un escenario complejo como la búsqueda y filtrado de información.
Si nos vemos en la necesidad de recibir parámetros para personalizar nuestras consultas, valdría la pena separar toda esta lógica en módulos nuevos.
app/
├─ ecommerce/
│ ├─ catalog/
│ │ ├─ finders/
│ │ │ ├─ product_finder.ex
...
¿Un pipeline de Brodway? No hay problema :D
app/
├─ ecommerce/
│ ├─ catalog/
│ │ ├─ finders/
│ │ │ ├─ product_finder.ex
│ │ ├─ pipeplines/
│ │ │ ├─ profit_pipeline.ex
...
¿Un cliente para una API externa?
En este caso promovemos el directorio http al primer nivel, ya que puede no ser exclusivo de un contexto y forma parte de la infraestructura.
app/
├─ ecommerce/
│ ├─ catalog/
│ │ ├─ finders/
│ │ │ ├─ product_finder.ex
│ │ ├─ pipeplines/
│ │ │ ├─ profit_pipeline.ex
├─ http/
│ ├─ crm_api.ex
...
También podemos usar el conocido directorio shared/, donde también podríamos promover nuestro modulo de autorización:
app/
├─ ecommerce/
│ ├─ catalog/
│ │ ├─ finders/
│ │ │ ├─ product_finder.ex
│ │ ├─ pipeplines/
│ │ │ ├─ profit_pipeline.ex
├─ shared/
│ ├─ http/
│ │ ├─ crm_api.ex
Otra forma de seguir escalando nuestra estructura de directorios seria agrupar nuestros módulos por la capa a la que pertenecen:
app/
├─ ecommerce/
│ ├─ accounts/
│ │ ├─ domain/
│ │ │ ├─ schemas/
│ │ │ │ ├─ user.ex
│ │ │ │ ├─ user_token.ex
│ │ ├─ application/
│ │ │ ├─ accounts.ex
│ │ │ ├─ user_creator.ex
│ │ ├─ infrastructure/
│ │ │ ├─ jobs
│ │ │ │ ├─ confirmation_email_job.ex
│ │ │ ├─ emails
│ │ │ │ ├─ user_email.ex
├─ shared/
│ ├─ infrastructure/
│ │ ├─ http/
│ │ │ ├─ crm_api.ex
│ ├─ application/
│ │ ├─ access_control.ex
...
Una opción adicional cuando nuestros casos de uso crecen, es organizarlos por el tipo de operación que realizan:
app/
├─ ecommerce/
│ ├─ accounts/
│ │ ├─ application/
│ │ │ ├─ accounts.ex
│ │ │ ├─ create/
│ │ │ │ ├─ user_creator.ex
...
Dependiendo de nuestra aplicación, esto podría ser excesivo o necesario. Todo depende del contexto.
Umbrella al rescate
Como hemos visto, una aplicación puede crecer rápidamente y salirse de control. Una solución común es separar una aplicación en múltiples servicios, algunos patrones con los que se decide como separar estas nuevas aplicaciones pueden ser por subdominio o por business capability.
Aunque tiene sus ventajas, construir servicios separados en repositorios separados conlleva nueva complejidad en cuanto al desarrollo y comunicación de los nuevos servicios.
Afortunadamente, Elixir cuenta con una herramienta llamada proyectos umbrella. Algo así como una aplicación de aplicaciones.
my_app_umbrella/
├─ apps/
│ ├─ ecommerce/
│ │ ├─ accounts/
│ │ │ ├─ domain/
│ │ │ │ ├─ schemas/
│ │ │ │ │ ├─ user.ex
│ │ │ │ │ ├─ user_token.ex
│ │ │ ├─ application/
│ │ │ │ ├─ accounts.ex
│ │ │ │ ├─ create/
│ │ │ │ │ ├─ user_creator.ex
│ │ │ ├─ infrastructure/
│ │ │ │ ├─ jobs
│ │ │ │ │ ├─ confirmation_email_job.ex
│ │ │ │ ├─ emails
│ │ │ │ │ ├─ user_email.ex
│ │ ├─ catalog/
│ │ │ ├─ domain/
│ │ │ │ ├─ schemas/
│ │ │ │ │ ├─ category
│ │ │ │ │ ├─ product.ex
│ │ │ ├─ application/
│ │ │ │ ├─ find/
│ │ │ │ │ ├─ product_finder.ex
│ │ │ │ ├─ catalog.ex
│ │ │ ├─ infrastructure/
│ │ │ │ ├─ pipeplines/
│ │ │ │ │ ├─ profit_pipeline.ex
│ │ ├─ shopping_cart/
│ │ │ ├─ domain/
│ │ │ │ ├─ schemas/
│ │ │ │ │ ├─ cart.ex
│ │ │ │ │ ├─ cart_item.ex
│ │ │ ├─ application/
│ │ │ │ ├─ shopping_cart.ex
│ │ ├─ shared/
│ │ │ ├─ infrastructure/
│ │ │ │ ├─ http/
│ │ │ │ │ ├─ crm_api.ex
│ │ │ ├─ application/
│ │ │ │ ├─ access_control.ex
│ ├─ ecommerce_web/
│ │ ├─ schemas/
│ │ │ ├─ user_schema.ex
│ │ ├─ live/
│ │ ├─ controllers/
│ │ │ ├─ product_controller.ex
│ │ │ ├─ category_controller.ex
│ ├─ backoffice/
│ │ ├─ support/
│ │ │ ├─ domain/
│ │ │ │ ├─ schemas/
│ │ │ │ │ ├─ ticket.ex
│ │ │ ├─ application/
│ │ │ │ │ ├─ tickets.ex
│ ├─ backoffice_web/
│ │ ├─ schemas/
│ │ ├─ live/
│ │ ├─ controllers/
│ │ │ ├─ product_controller.ex
├─ README.md
Con un proyecto umbrella ahora tenemos distintas aplicaciones: ecommerce, ecommerce_web, backoffice y backoffice_web. Con esto eliminamos la necesidad de separar nuestra aplicación original en múltiples repositorios si se vuelve muy grande, lo que agregaría mucho trabajo para manejar y orquestar el desarrollo.
Los proyectos umbrella nos proveen algunas ventajas:
- Desarrollo monorepo
- Puedes construir, probar y desplegar cada aplicación por separado si asi lo deseas.
- Una aplicación puede tener disponible otra si esta define como una dependencia interna (dentro de la umbrella)
Dado que comparten dependencias y la configuración de las mismas, es importante tomarlo en cuenta, ya que al no ser aplicaciones totalmente independientes pudiera causar conflictos.
¿Cuándo comenzar con una aplicación de Phoenix normal y cuando con una umbrella?
Si tu proyecto está empezando y no sabes a ciencia cierta hacia donde va o que tan grande puede ser, comienza simple, una aplicación de Phoenix será suficiente y con un poco de disciplina, promover directorios hacia su propio contexto o su propia app será sencillo.
Si lo que estás desarrollando es un producto con varios subdominios, aunque comiences con uno solo, pero esperas desarrollar el resto eventualmente. O cuando ese subdominio es considerablemente complejo (es un core subdomain) puedes comenzar con un proyecto umbrella.
Tu aplicación es tuya y tú sabes de qué trata
Los frameworks suelen ofrecer una base para comenzar a organizar tu aplicación, sin embargo, no conocen muchos detalles que tú si, quien la desarrolla. No saben de qué trata, que tan grande puede ser que tan simple o compleja es la lógica de negocio. Por eso no pueden ofrecer una guía que sirva para todos los casos y para todos los tamaños.
Tú eres el dueño de tu aplicación y conoces mejor tus necesidades. ¿No te gusta la idea de separar en ecommerce y backoffice? Bien, elimínalas, es tu aplicación :D.
¿No necesitas que tu estructura de directorios te diga a que capa pertenecen los módulos? Excelente!
El punto es que la arquitectura de nuestra aplicación eventualmente necesita evolucionar, pero rara vez esto sucede. Generalmente, se permanece con la arquitectura y estructura original, aunque esta ya no cumpla los requerimientos del producto.
Tener una heurística base nos permite evaluar opciones e implementar la que mejor se ajuste a nuestros requerimientos y nuestra experiencia :D
Links de interes:
- https://medium.com/very-big-things/towards-maintainable-elixir-the-core-and-the-interface-c267f0da43
- https://ulisses.dev/elixir/2022/03/04/elixir-modules-files-directories-and-naming-conventions.html
- https://remote.com/blog/introducing-phx_gen_solid
- https://martinfowler.com/eaaCatalog/serviceLayer.html
- https://aaronrenner.io/2019/09/18/application-layering-a-pattern-for-extensible-elixir-application-design.html